
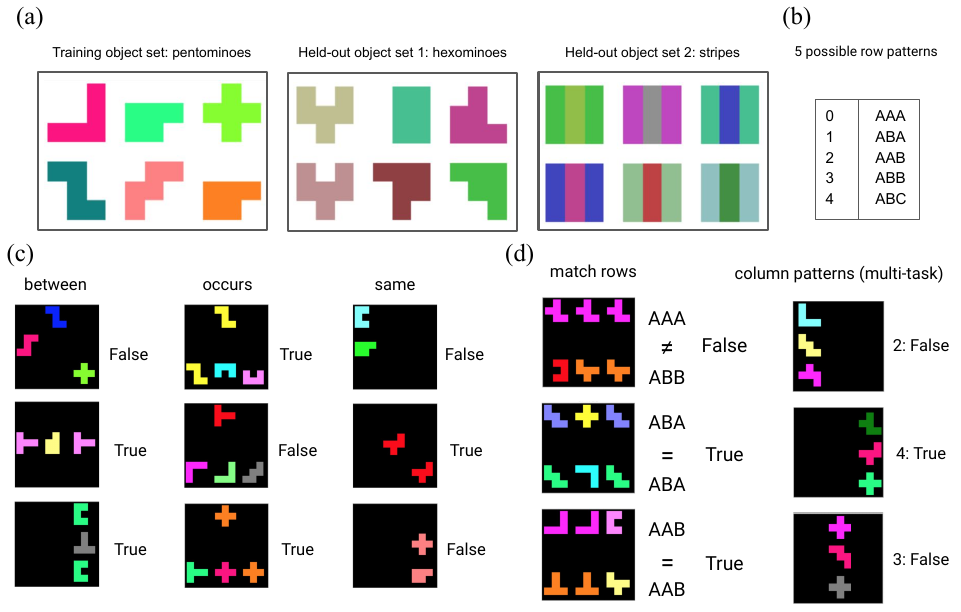
Abductive Learning
Towards Bridging Machine Learning and Logical Reasoning
(Press ? for help, n and p for next and previous slide)
Machine Perception
and Reasoning
Machine Learning
... now is VERY good at

Machine Learning
... now is NOT very good at

Machine Learning
... now is way worse than human at

Question: Solve -42*r + 27*c = -1167 and 130*r + 4*c = 372 for r.
Answer: 4
Question: Calculate -841880142.544 + 411127.
Answer: -841469015.544
Question: Let x(g) = 9*g + 1. Let q(c) = 2*c + 1. Let f(i) = 3*i - 39. Let w(j) = q(x(j)). Calculate f(w(a)).
Answer: 54*a - 30
Question: Let e(l) = l - 6. Is 2 a factor of both e(9) and 2?
Answer: False
Question: Let u(n) = -n**3 - n**2. Let e(c) = -2*c**3 + c. Let l(j) = -118*e(j) + 54*u(j). What is the derivative of l(a)?
Answer: 546*a**2 - 108*a - 118
Question: Three letters picked without replacement from qqqkkklkqkkk. Give prob of sequence qql.
Answer: 1/110
A Modern Rephrase of Curve Fitting
Treating Reasoning as Perception


Treating Reasoning as Perception

- Hard to tell machines what we know;
- Hard to understand machines from what they learned.
Machine Reasoning
... is the very first task in AI


Machine Reasoning
- General Problem Solving
- Automated Theorem Proving
- Boolean Satisfiability
- Expert Systems
- Logic Programming
- Inductive Logic Programming
- Probabilistic Logic Programming
- Constraint Logic Programming, Answer Set Programming
- …
Symbolism
A physical symbol system has the necessary and sufficient means for general intelligent action.
— Allen Newell and Herbert A. Simon, 1975.
Real objects seldom wear unique identifiers or preannounce their existence like the cast of a play.
— Stuart Russell, 2015.
The Separated Perception and Reasoning

Bridging Machine Learning and Reasoning

Too Many Attempts
- Multi-valued / Fuzzy Logic;
- How to define “\(\rightarrow\)” (implication);
- Statistical Relational Learning &
Probabilistic Logic Programming;- Probabilistic Graphical Model;
- Independence assumptions, pseudo-likelihood
- Neural Symbolic Learning;
- Embedding representation;
- Fuzzy logic operators;
- Abductive Reasoning


Deduction Abduction


A Human Example
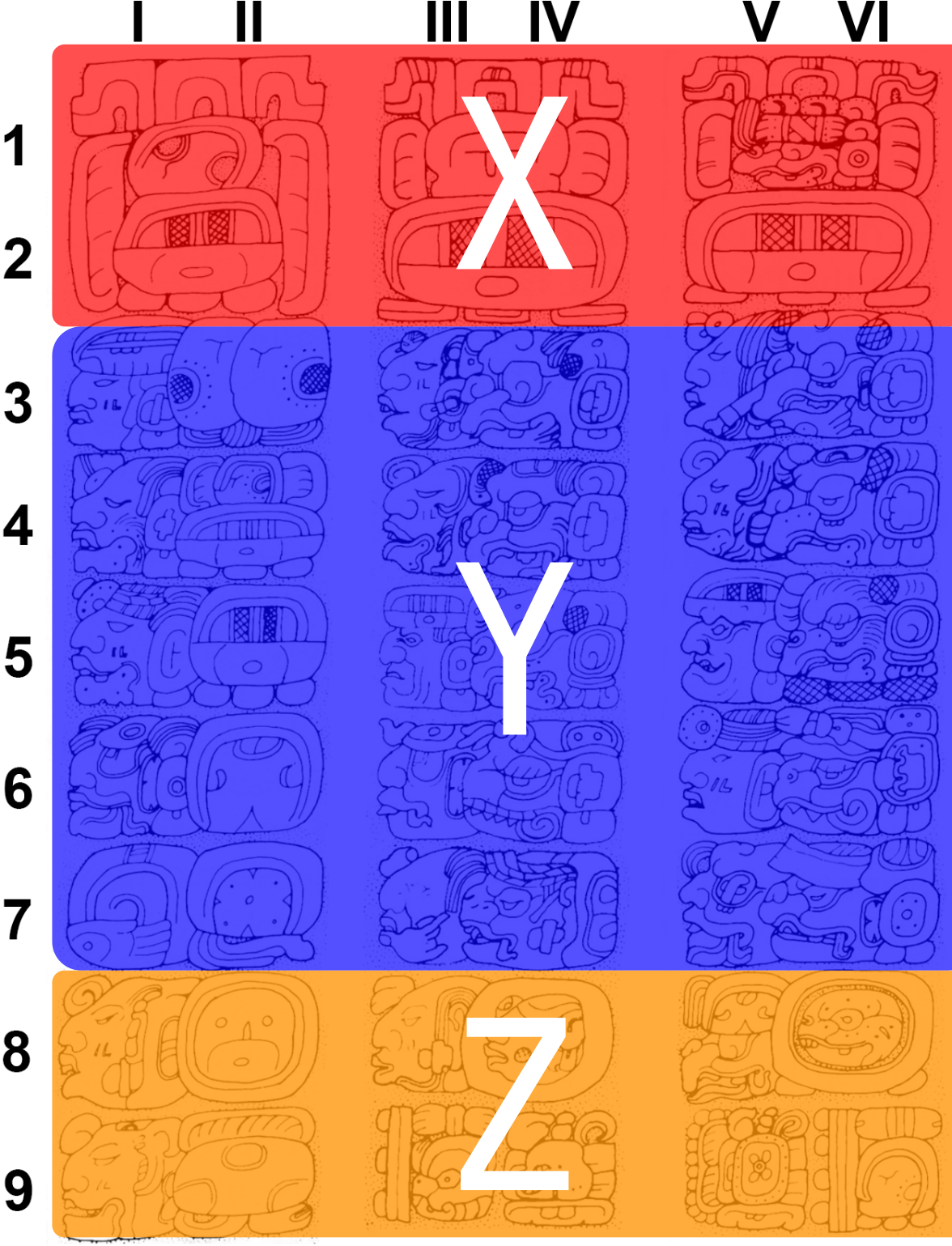
The Mayan Calendars
Temple of the Foliated Cross

Tablet in the temple

It records some big events and their dates.
The calendar
- Row 1-2: \(X\)
- Row 3-7: \(Y\)
- Row 8-9: \(Z\)
Calculation \[ X\oplus Y=Z \]
The calendar
- Col. I, III, V: Values \(a_i\)
- Col. II, IV, VI: Units \(u_i\)
Numbers
- \(X=X_0\)
- \(Y=\sum_{i=3}^7 a_i\cdot u_i\)
- \(Z=\sum_{i=8}^9 a_i\cdot u_i\)

The “head variants”

Cracking the glyphs


Cracking the glyphs
- Perception:
- \(\text{Glyphs}\) (image) \(\mapsto\) \(\text{Numbers}\) (symbol);
- Abductive Reasoning:
- Observation: the equations on tablet are correct;
- Background Knowledge:
- Structure: \(X\oplus Y=Z\)
- Calculation rules: 20-based \(\oplus\);
- Trial-and-errors:
- Until perception and reasoning are consistent.
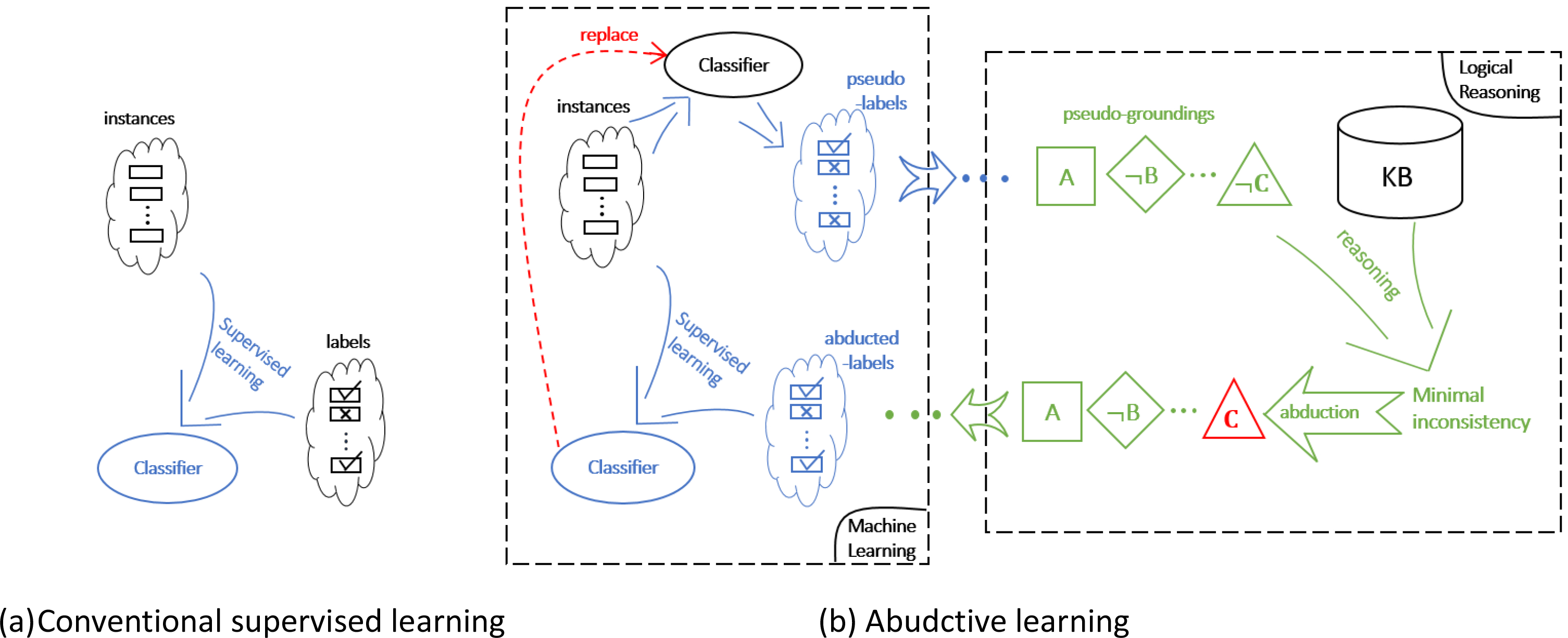
Abductive Learning
The Framework
- Input:
- Examples: \(D=\{\langle \mathbf{x}_1,y_1\rangle,\ldots,\langle \mathbf{x}_m,y_m\rangle\}\);
- Background knowledge: \(KB\);
- Primitive symbols (pseudo labels): \(\mathcal{P}=\{p_1,p_2,\ldots\}\);
- Output: Hypothesis \(H=p\cup\Delta_C\);
- Perception (machine learning) model \(p:\mathcal{X}\mapsto \mathcal{P}\);
- Knowledge (reasoning) model \(\Delta_C\), where:
\[ KB\cup\Delta_C\cup p(\mathbf{x}_i)\models y_i. \]
A Simplified Task
- Handwritten Equation Decipherment:
- Untrained perception model (CNN);
- Unknown operation rules: add / logical xor / etc.
- Learn perception and reasoning jointly;
- Challenge:
- Labels for training perception model need to be inferred (abduced) by logic reasoning;
- Logical Reasoning require perceived symbols as input;


Handwritten Equation Decipherment
- Input (with label of equation correctness):

- Output:
- Well-trained CNN \(p:\mathbb{R}^d\mapsto\{0,1,+,=\}\)
- Operation rules:
- e.g.
1+1=10,1+0=1,…(add);1+1=0,0+1=1,…(xor).
- e.g.
Background knowledge 1
Equation structure (DCG grammars):

- All equations are
X+Y=Z; - Digits are lists of
0and1.
Background knowledge 2
Binary operation:

- Calculated bit-by-bit, from the last to the first;
- Allow carries.
Model Structure

- Machine learning:
- Perceptions from raw data ⟶ primitive logic facts;
- Logical abduction:
- Abduces pseudo label (primitive logic facts facts) to re-train \(p\);
- Learns logical rules \(\Delta_C\) to complete the reasoning from primitive logic facts ⟶ final concept;
- Optimise the consistency of hypothesis and data.
Implementation
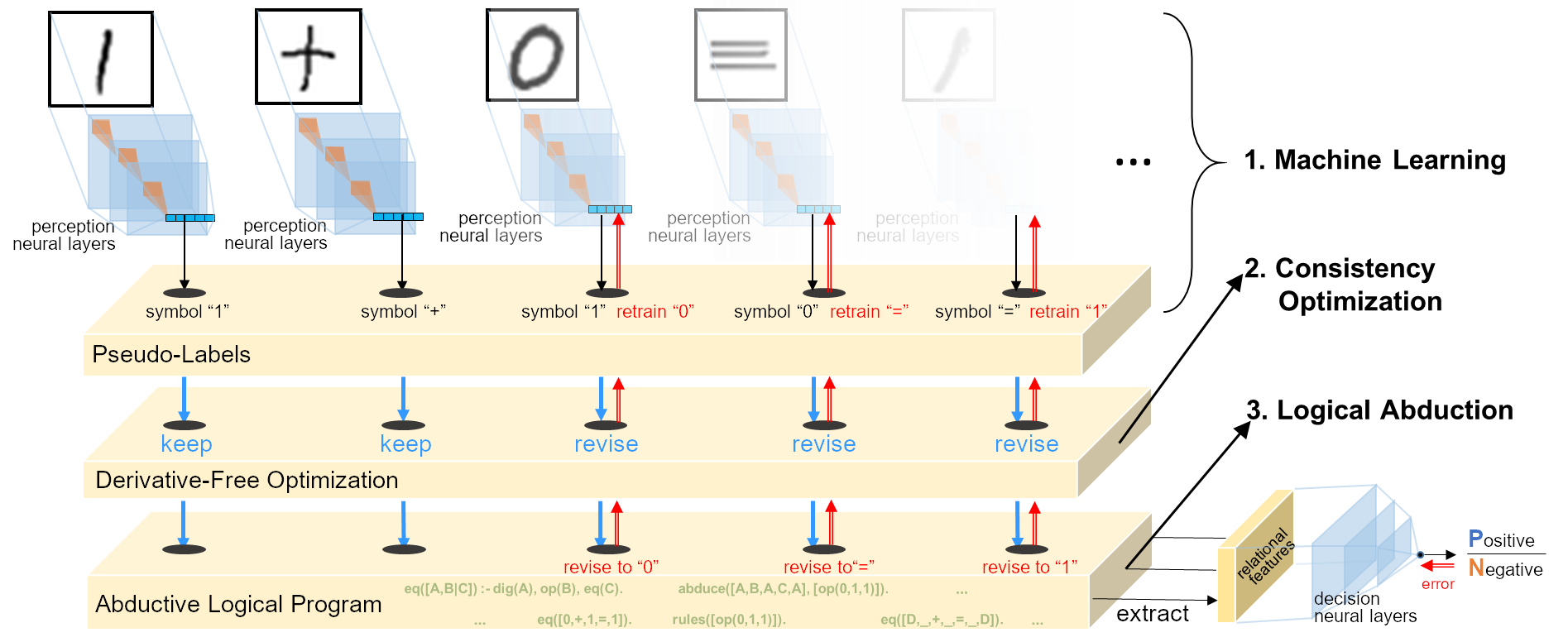
- Perception model: Convolutional Neural Network
- Abductive reasoning model: Abductive Logic Programming
- Consistency optimisation: Derivative-Free Optimisation (RACOS)
Formulation
Intuition:
- Maximise the number of instances in \(D\) that are consistent with \(H\):
here \(\text{Con}(H\cup D)\) is the size of subset \(\hat{D}_C\in D\) consistent with \(H\):
Optimisation in sketch
When perception model $p$ is fixed:
- Recognise pseudo-labels \(p^t(\mathbf{x})=\cup_i p^t(\mathbf{x}_i)\) from raw data;
- Since \(p\) is untrained (no ground truth label), \(p^t(\mathbf{x})\) might be wrong;
- Mark up the “possibly wrong” pseudo-labels \(\delta(p^t(X))\), where \(\delta\) is a function to guess which perceived symbols are wrong.
- Maximise consistency by optimising \(\delta\);
- Abduce the revised pseudo-labels \(r_\delta(X)\) and reasoning model \(\Delta_C\) based on \(\delta\).
Optimisation in sketch
When reasoning model $\Delta_C$ is fixed
- Using revised pseudo-label \(r_\delta(X)\) to train perception model \(p^{t+1}\).
Wrap-it-up
Training Log
%%%%%%%%%%%%%% LENGTH: 7 to 8 %%%%%%%%%%%%%%
This is the CNN's current label:
[[1, 2, 0, 1, 0, 1, 2, 0], [1, 1, 0, 1, 0, 1, 3, 3], [1, 1, 0, 1, 0, 1, 0, 3], [2, 0, 2, 1, 0, 1, 2], [1, 1, 0, 0, 0, 1, 2], [1, 0, 1, 1, 0, 1, 3, 0], [1, 1, 0, 3, 0, 1, 1], [0, 0, 2, 1, 0, 1, 1], [1, 3, 0, 1, 0, 1, 1], [1, 0, 1, 1, 0, 1, 3, 3]]
****Consistent instance:
consistent examples: [6, 8, 9]
mapping: {0: '+', 1: 0, 2: '=', 3: 1}
Current model's output:
00+1+00 01+0+00 0+00+011
Abduced labels:
00+1=00 01+0=00 0+00=011
Consistent percentage: 0.3
****Learned Rules:
rules: ['my_op([0],[0],[0,1])', 'my_op([1],[0],[0])', 'my_op([0],[1],[0])']
Train pool size is : 22
Training Log
...
This is the CNN's current label:
[[1, 1, 0, 1, 2, 1, 3, 3], [1, 3, 0, 3, 2, 1, 3], [1, 0, 1, 1, 2, 1, 3, 3], [1, 1, 0, 1, 0, 1, 3, 3], [1, 0, 1, 1, 2, 1, 3, 3], [1, 1, 0, 1, 0, 1, 3, 3], [1, 0, 3, 3, 2, 1, 1], [1, 1, 0, 1, 2, 1, 3, 3], [1, 1, 0, 1, 2, 1, 3, 3], [3, 0, 1, 1, 2, 1, 1]]
****Consistent instance:
consistent examples: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
mapping: {0: '+', 1: 0, 2: '=', 3: 1}
Current model's output:
00+0=011 01+1=01 0+00=011 00+0=011 0+00=011 00+0=011 0+01=00 00+0=011 00+0=011 1+00=00
Abduced labels:
00+0=011 01+1=01 0+00=011 00+0=011 0+00=011 00+0=011 0+01=00 00+0=011 00+0=011 1+00=00
Consistent percentage: 1.0
****Learned feature:
rules: ['my_op([1],[0],[0])', 'my_op([0],[1],[0])', 'my_op([1],[1],[1])', 'my_op([0],[0],[0,1])']
Train pool size is : 77
Experimental Results
Setting
- Data: length 5-26 equations, each length 300 instances
- DBA: MNIST equations;
- RBA: Omniglot equations;
- Binary addition and exclusive-or.
- Compared methods:
- ABL-all: Our approach with all training data
- ABL-short: Our approach with only length 7-10 equations;
- DNC: Memory-based DNN;
- Transformer: Attention-based DNN;
- BiLSTM: Seq-2-seq baseline;
Prediction Accuracy
Test Acc. vs Eq. length


Mutual Beneficial Perception & Reasoning
Training Acc.


Model Reuse
Reusing $p$ (L) vs reusing $\Delta_C$ (R)


Conclusion
Take-home message
- No embedding/gradients; Utilises full-featured first-order logic;
- Better generalisation;
- Handles recursive knowledge;
- Takes advantage of over 60 years of symbolic AI research directly;
- Abductive reasoning connects high-level reasoning and low-level perception;
- Abduction is neither sound or complete, humans/machines need trial-and-errors.
- The dividing line between high-level and low-level is unclear, how to combine symbolic and sub-symbolic AI more efficiently is still an open question.
Human-Like Computing
Each Play to Their Strengths