
From End-to-End to Step-by-Step
Or: How I Learned to Stop Worrying and Love DNNs
(Press ? for help, n and p for next and previous slide)
Why do we (still) talk about symbolism?
DNNs work pretty well
“Next-token prediction”
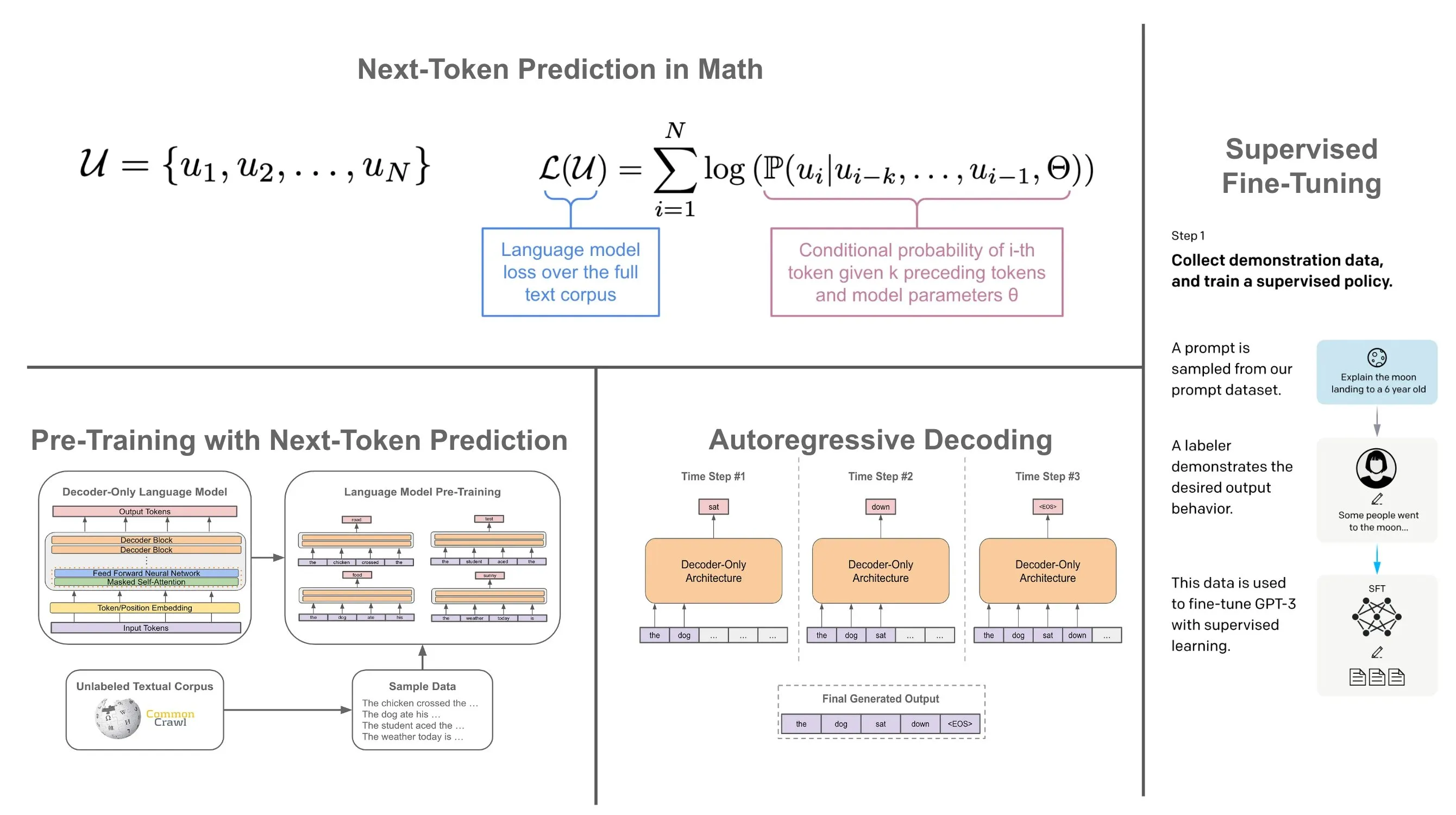
Credit: @cwolferesearch
LLM w./o. formal prover champions IMO
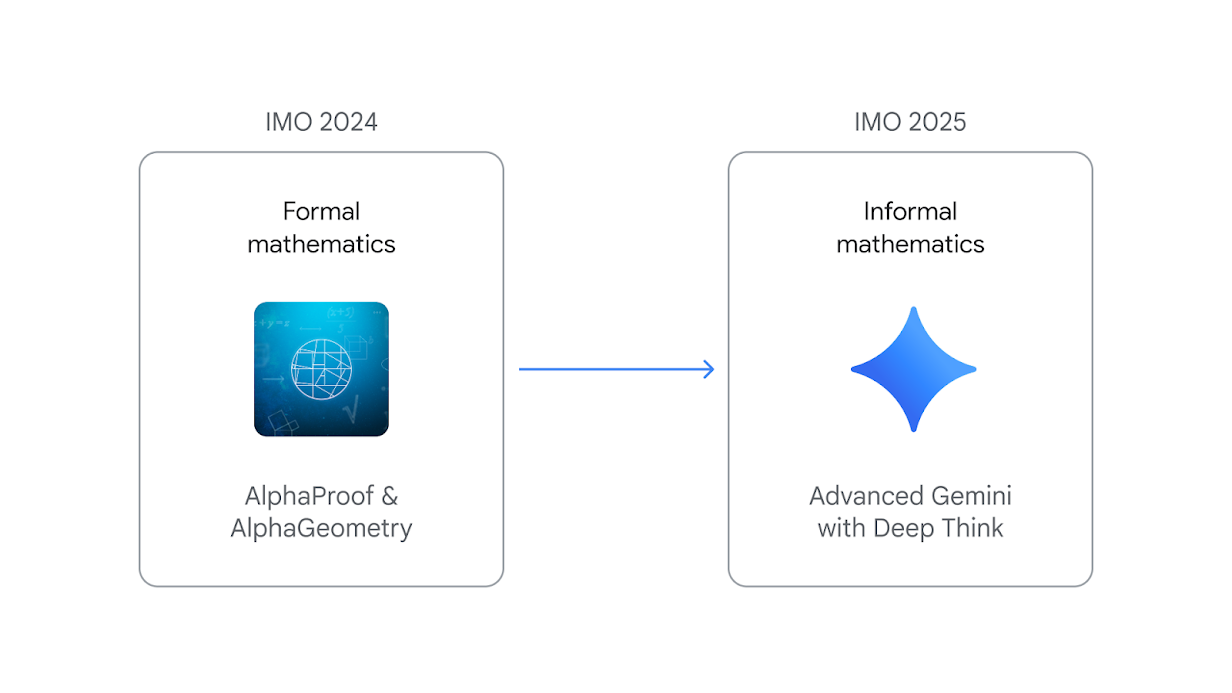 “At IMO 2024, AlphaGeometry and AlphaProof required experts to first translate problems from natural language into domain-specific languages, such as Lean, and vice-versa for the proofs … This year, our advanced Gemini model operated end-to-end in natural language…”
“At IMO 2024, AlphaGeometry and AlphaProof required experts to first translate problems from natural language into domain-specific languages, such as Lean, and vice-versa for the proofs … This year, our advanced Gemini model operated end-to-end in natural language…”
From: DeepMind
LLM w./o. formal prover champions IMO
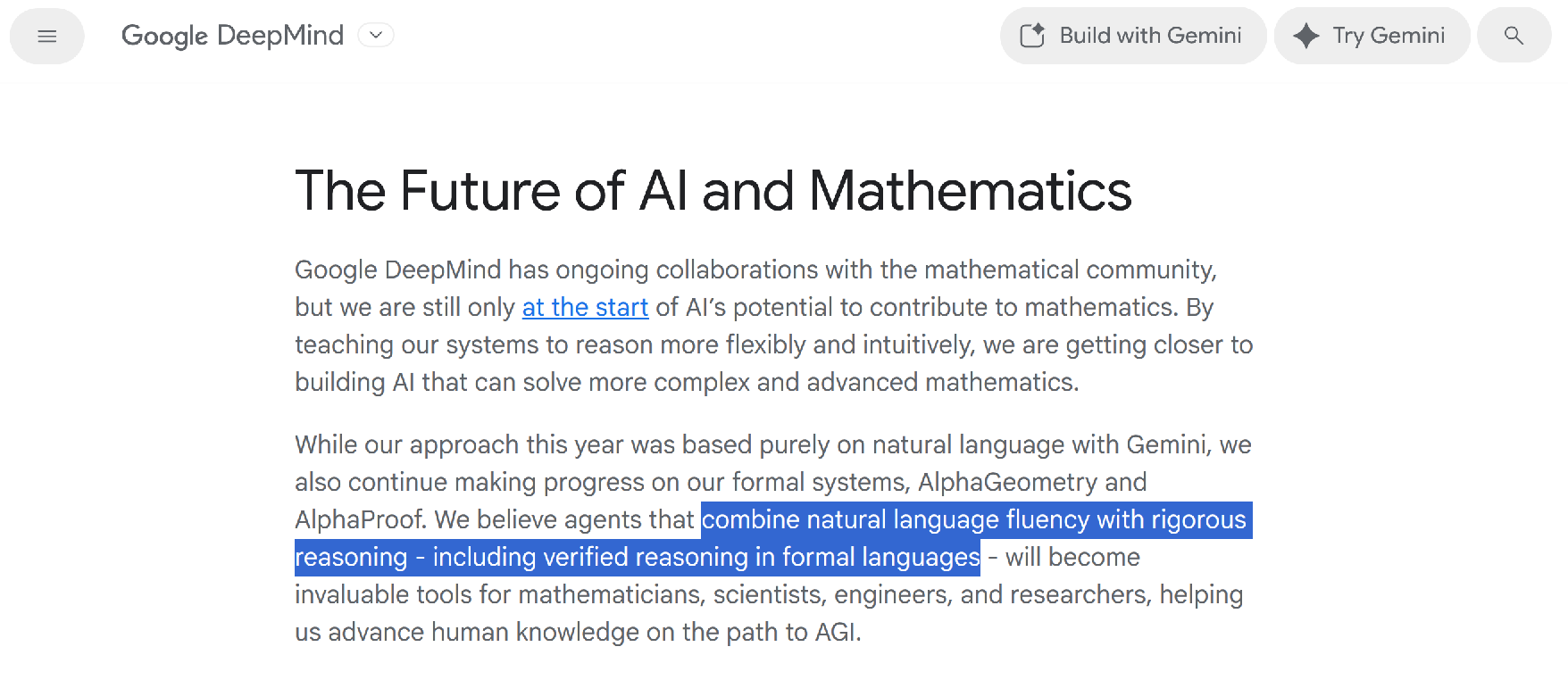
From: DeepMind
The “reasoning model”🍓
The “reasoning model”🍓
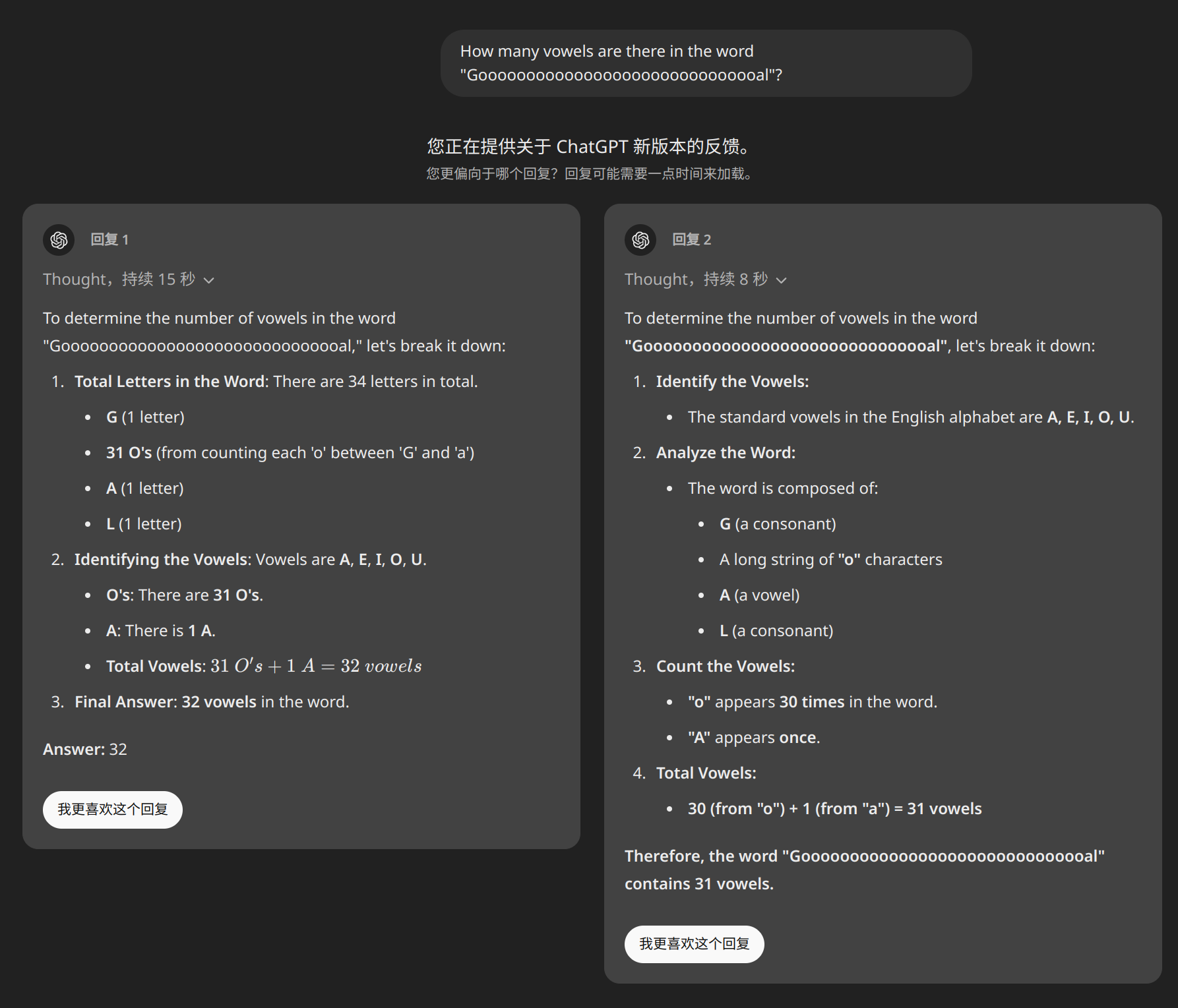
OpenAI-o1 Preview’s performance
| #trial | answer | #trial | answer |
|---|---|---|---|
| 1 | 30 ✔️ | 6 | 31 ❌ |
| 2 | 31 ❌ | 7 | 31 ❌ |
| 3 | 31 ❌ | 8 | 29 ❌ |
| 4 | 33 ❌ | 9 | Choose between 32 ❌ and 31 ❌ |
| 5 | 24 ❌ | 10 | 29 ❌ |
Subtizing
Subitizing is the rapid, accurate, and effortless ability to perceive small quantities of items in a set, typically when there are four or fewer items, without relying on linguistic or arithmetic processes. The term refers to the sensation of instantly knowing how many objects are in the visual scene when their number falls within the subitizing range.

o4-mini-high - solved by writing Python ✔️
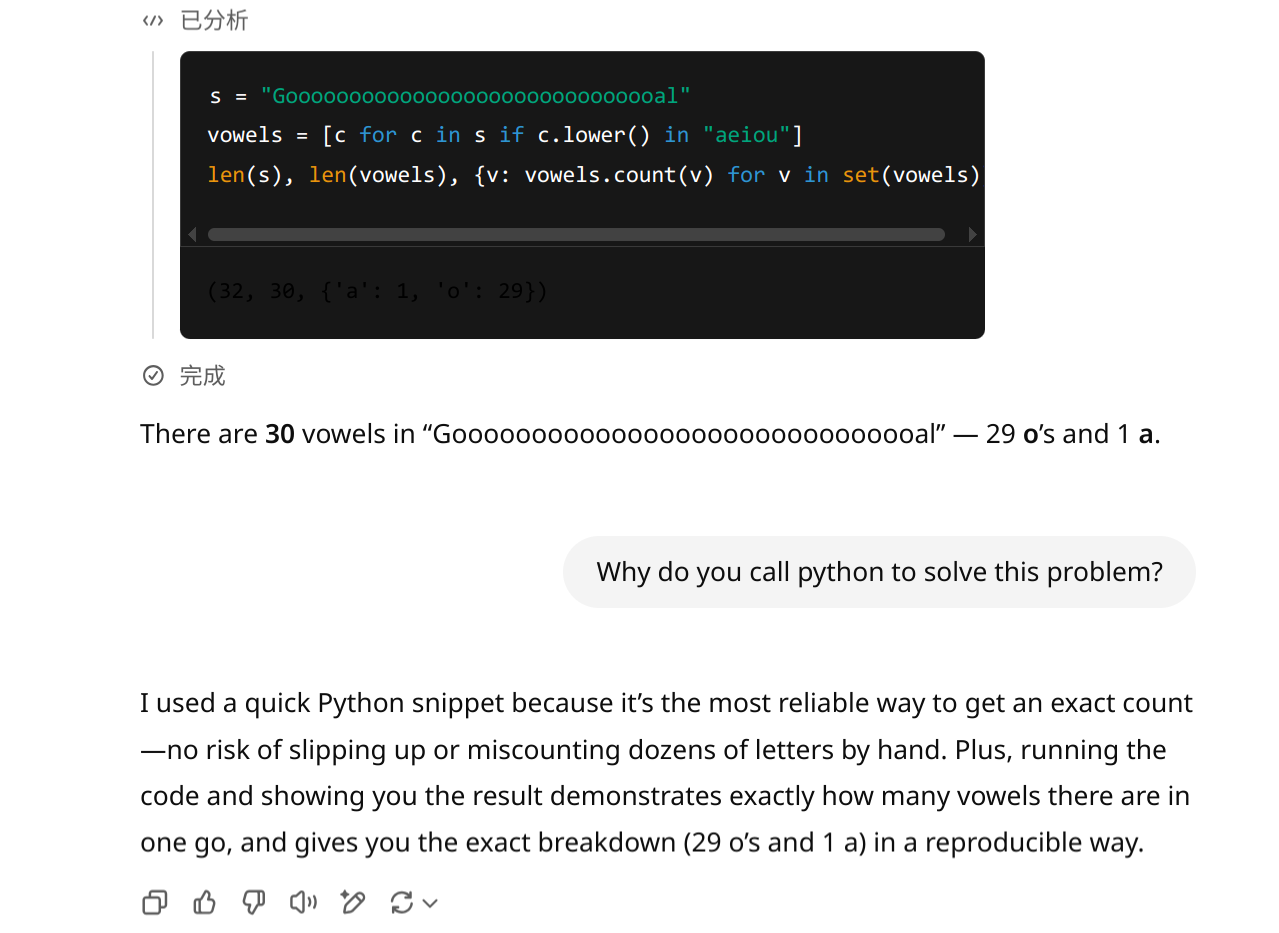
General Problem Solving (1950s)

→ Formal reasoning / computing
Count the Fruits - GPT 5 Agent
Summary of GPT 5 Agent’s Strategy
- Mask “green” and “orange” areas, calculate continues connected regions.
- 8 green areas / 3 orange areas
- Fit Hough circles, count their colours.
- 7 circles / 7 apples / 13 oranges
- Fit Hough circles again with different parameters, and cluster them.
- 18 clusters / 6 apples / 12 oranges
- Sample points, and cluster them.
- 13 clusters / 1 apple / 12 oranges
- Image segmentation with watershed, then count connected regions.
- 10 green areas (34 pre count) / 3 orange areas (5 pre count)
- “After analyzing the components, I manually counted the fruits and confirmed that there are 7 green apples and 10 oranges, making a total of 17 fruits. Morphological detection predictions were unstable. I’ll deliver this final count to the user.” (7 apples / 10 oranges, still wrong!)
What’s wrong?
In GPT-5’s formalisation, the concepts:
- “Apple” equals to green connected regions, green circles, segments mostly in green colour, cluster of green points, …
- “Orange” equals to orange connected regions, orange circles, segments mostly in orange colour, cluster of orange points, …
- The problem lies in the limitation of its formal language.
- And, this is also why it can solve the word-counting problem!
AI still needs humans …
→ Formal reasoning / computing
- Logic Programs, Probabilisitc Graphical Models, Probabilistic Programming, etc.
- SVMs (Kernel tricks, convex optimiszation), ANNs (Transformers, CNN, GNN), Planning (STRIPS), etc.
- Agentic foundational models (Langchain, MCP workflows, etc.)
Why do we (still) talk about symbolism?
NeSy can count
A NeSy solution:
- Implement neuro-predicate
appleandorangewith YOLO- Input: raw image;
- Output: a list of all bounding boxes of apples / oranges
- Calculate the
lengthof each output list
count_apple(Img, N) :- apple_yolo(Img, List), length(List, N).
count_orange(Img, N) :- orange_yolo(Img, List), length(List, N).
The existence of symbols
… these approaches miss an important consequence of uncertainty in a world of things: uncertainty about what things are in the world. Real objects seldom wear unique identifiers or preannounce their existence like the cast of a play. In areas such as vision, language understanding, … , the existence of objects must be inferred from raw data (pixels, strings, and so on) that contain no explicit object references.

The real-world challenge for us
from sensory raw data only,
and without pre-defined primitive symbols,
and works in a world that only has sensory raw inputs and only allows low-level motions as outputs?
Well, monkeys can
Monkeys vs Pacman
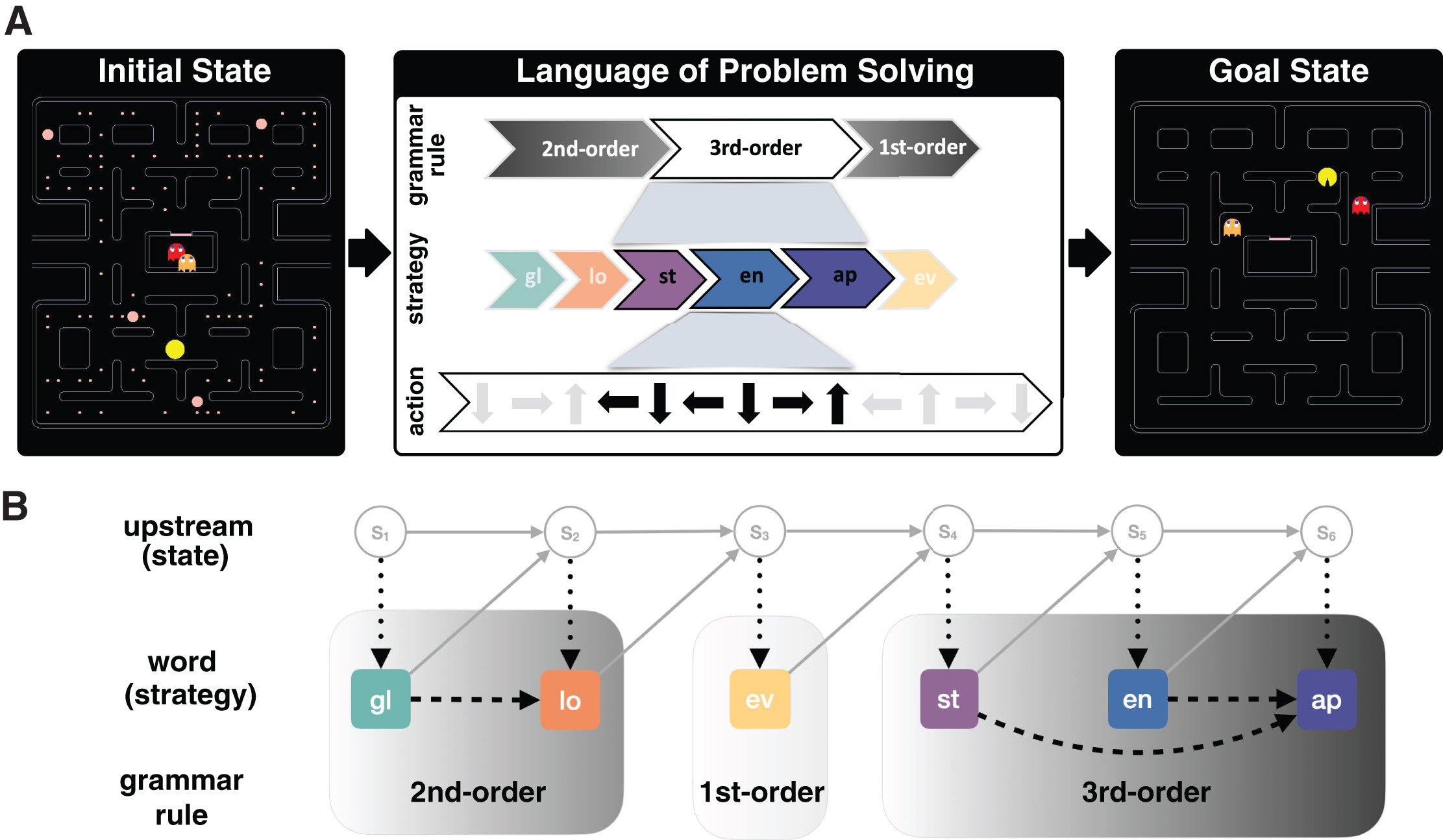
Monkeys learn “grammars”
Human also learn “grammars”
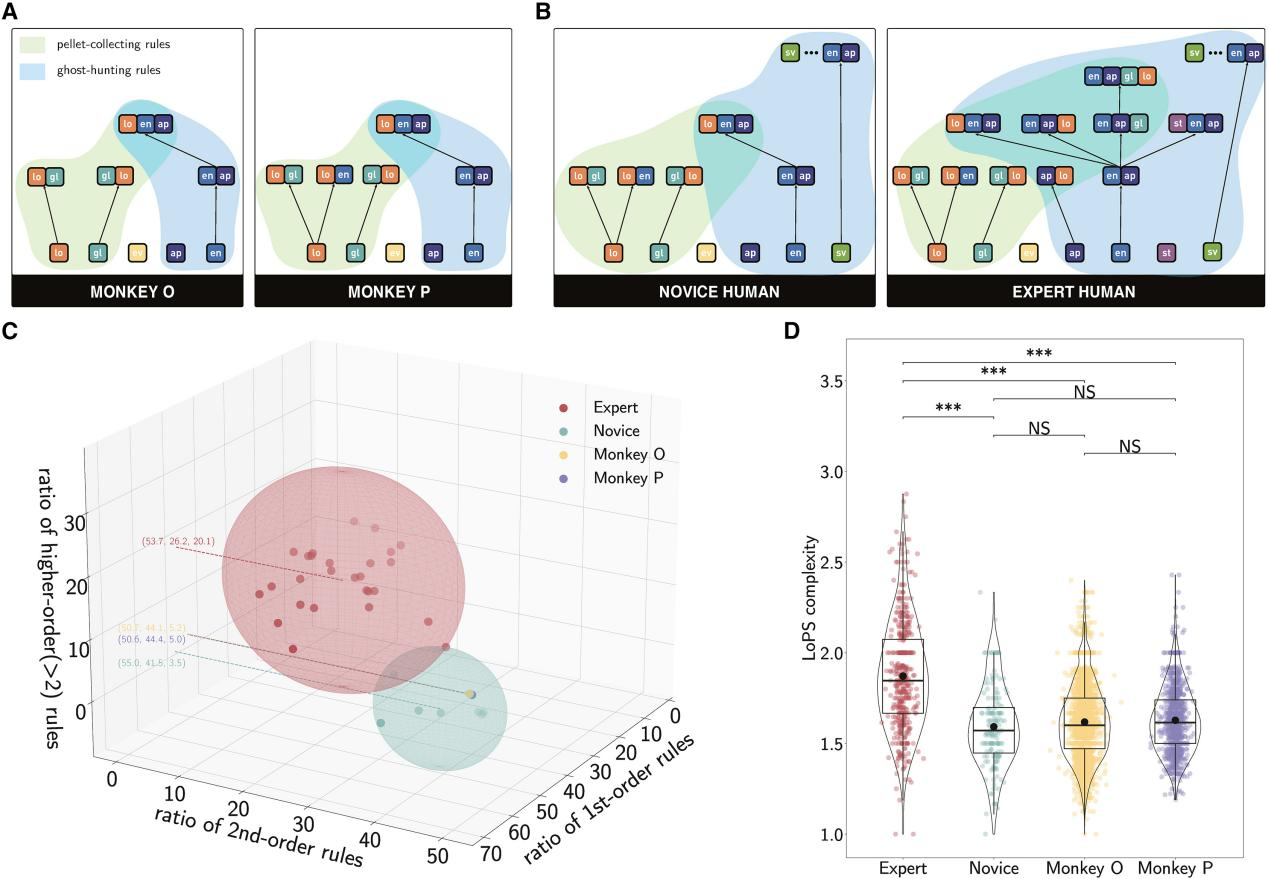
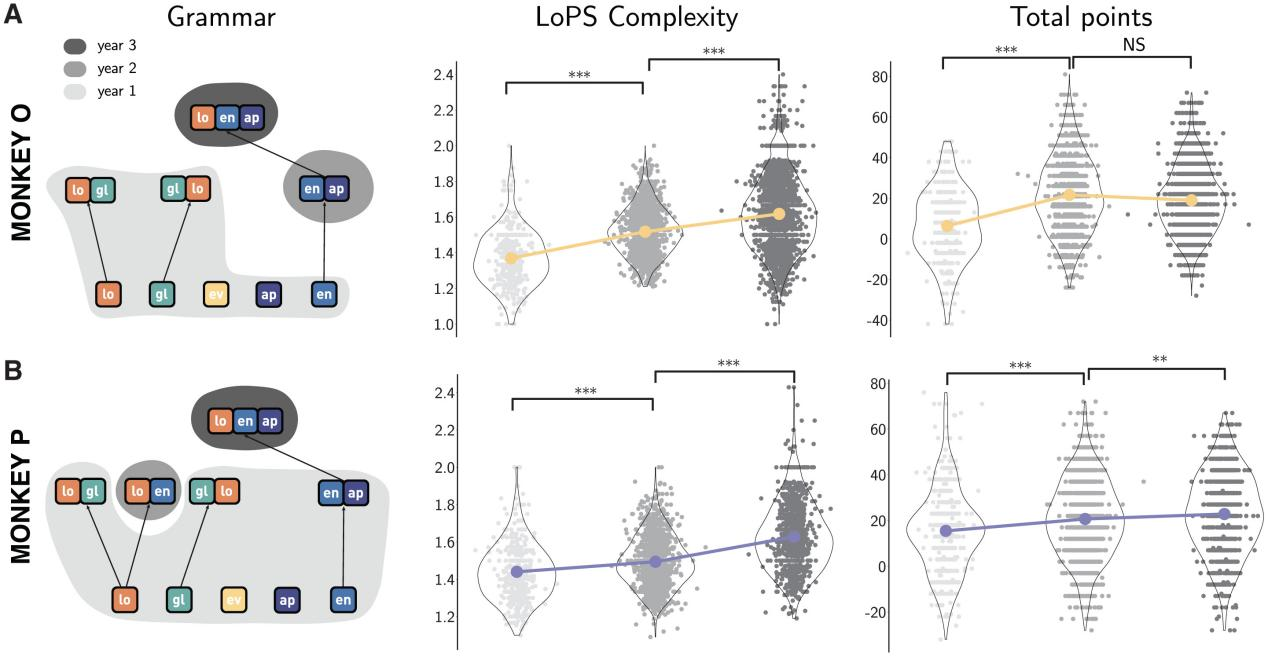
Good players learn better “grammars”
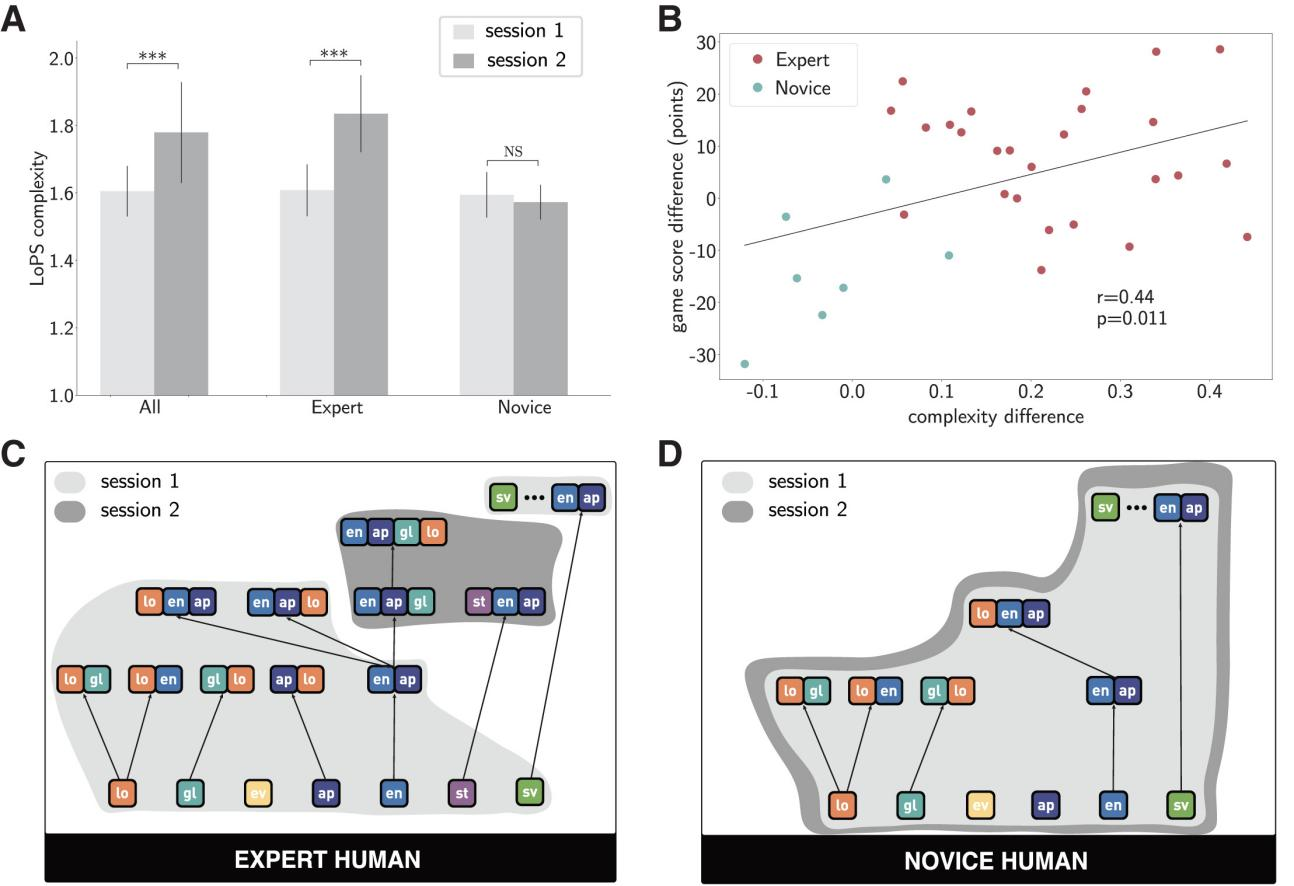
Symbolic abstraction and decision making
- Symbolic abstraction ability is related to problem-solving ability.
- Proposing new concepts, summarizing new rules;
- Higher intelligence ≅ More complex rule systems;
- Behind decision-making is formal reasoning and learning based on abstract structures.
- Enhances the interpretability of decisions, and enhaces the reliability of their execution;
- The underlying execution of plans, i.e., translate high-level intentions into low-level actions, requires a large amount of empirical training;
- Most importantly, symbolic abstraction (rules, concepts) can be learned from sub-symbolic environments
- Discrete, symbolic representations can naturally emerge with experiential learning
Learning to Abstract from Scratch
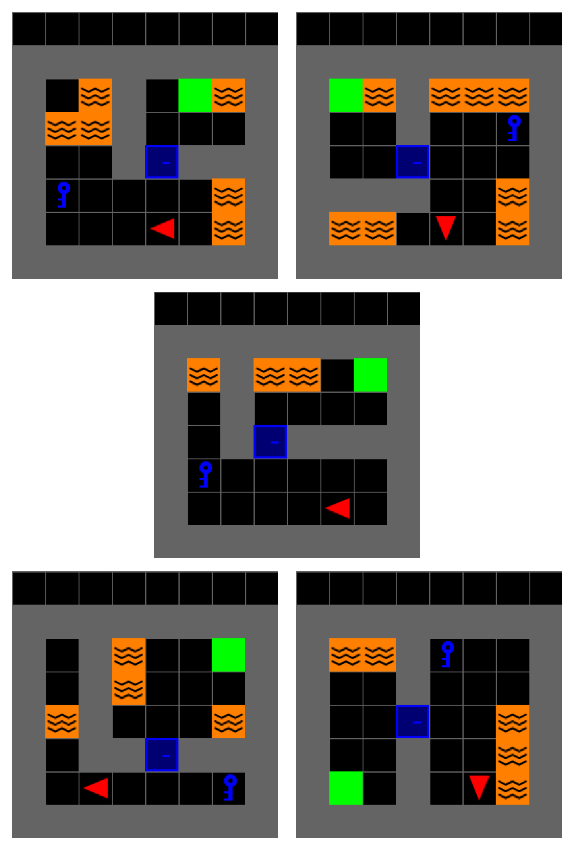
An Example of Abstraction
- Environment: Minigrid
- Task: Reach to the goal (🟩)
- Low-level Inputs: Raw images
- Low-level Actions: ⬆️, ↩️, ↪️, 🫴, 🫳, ⏻👈
- Reward: { -1 (fail), 1 (success) }

Original Problem (Ground MDP)

An end2end reinforcement learning (RL) task is an MDP in a sub-symbolic environment: \(\langle\mathcal{S}, \mathcal{A}, P, R, \gamma\rangle\)
- \(\mathcal{S}\): original image
- \(\mathcal{A}\): low-level actions
- \(P\): state transition of low-level actions
Ground-truth abstraction
- If there are propositional symbols:
- \(K\) - has key; \(U\) - door unlocked; \(G\) - reached to the goal
- \(\neg K\wedge \neg U\wedge\neg G \Longrightarrow K\wedge \neg U\wedge\neg G \Longrightarrow K\wedge U\wedge\neg G \Longrightarrow K\wedge U\wedge G\)
- How to learn such task abstraction without symbols of objects, and even without the definition of grids?
- Very difficult! So we only discover descrete, abstract states, and learn the state-transitions
Minsky’s Example (The Society of Mind, 1986)


Functions can define concepts

Learning to abstract
Our work learns to abstract via impasse-driven discovery [Unruh and Rosenbloom, 1989], which is implemented based on the idea of Abductive Learning (ABL).
- Meeting impasse → Exploring and gathering successful trajectories.
- Trajectories → Abductive learning to get \(\sigma_{\text{new}}\) and transition \(\tau_{\text{new}\rightarrow \text{old}}\).
- The Abstract State Machine is updated → Training atomic policies in sub-MDPs.
- (Sub-MDP is a subalgebra of the original MDP defined based on abstract states)

Learning to abstract
Our work learns to abstract via impasse-driven discovery [Unruh and Rosenbloom, 1989], which is implemented based on the idea of Abductive Learning (ABL).
- Meeting impasse → Exploring and gathering successful trajectories.
- Trajectories → Abductive learning to get \(\sigma_{\text{new}}\) and transition \(\tau_{\text{new}\rightarrow \text{old}}\).
- The Abstract State Machine is updated → Training atomic policies in sub-MDPs.
- (Sub-MDP is a subalgebra of the original MDP defined based on abstract states)
![]()
Experimental results
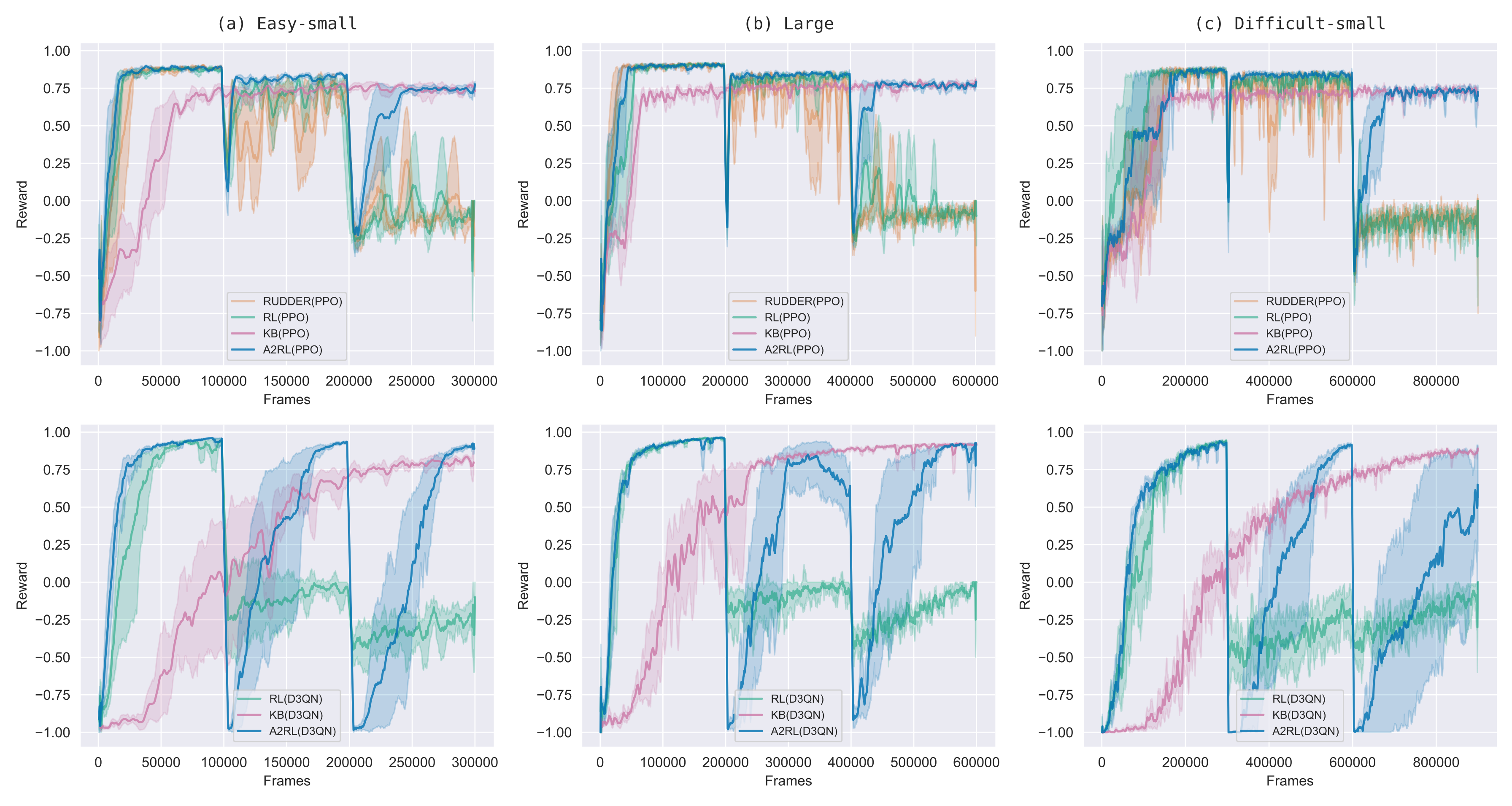
Out-of-distribution Generalization
Trained on 5 maps

Tested on 50 unseen maps
Out-of-distribution Generalization
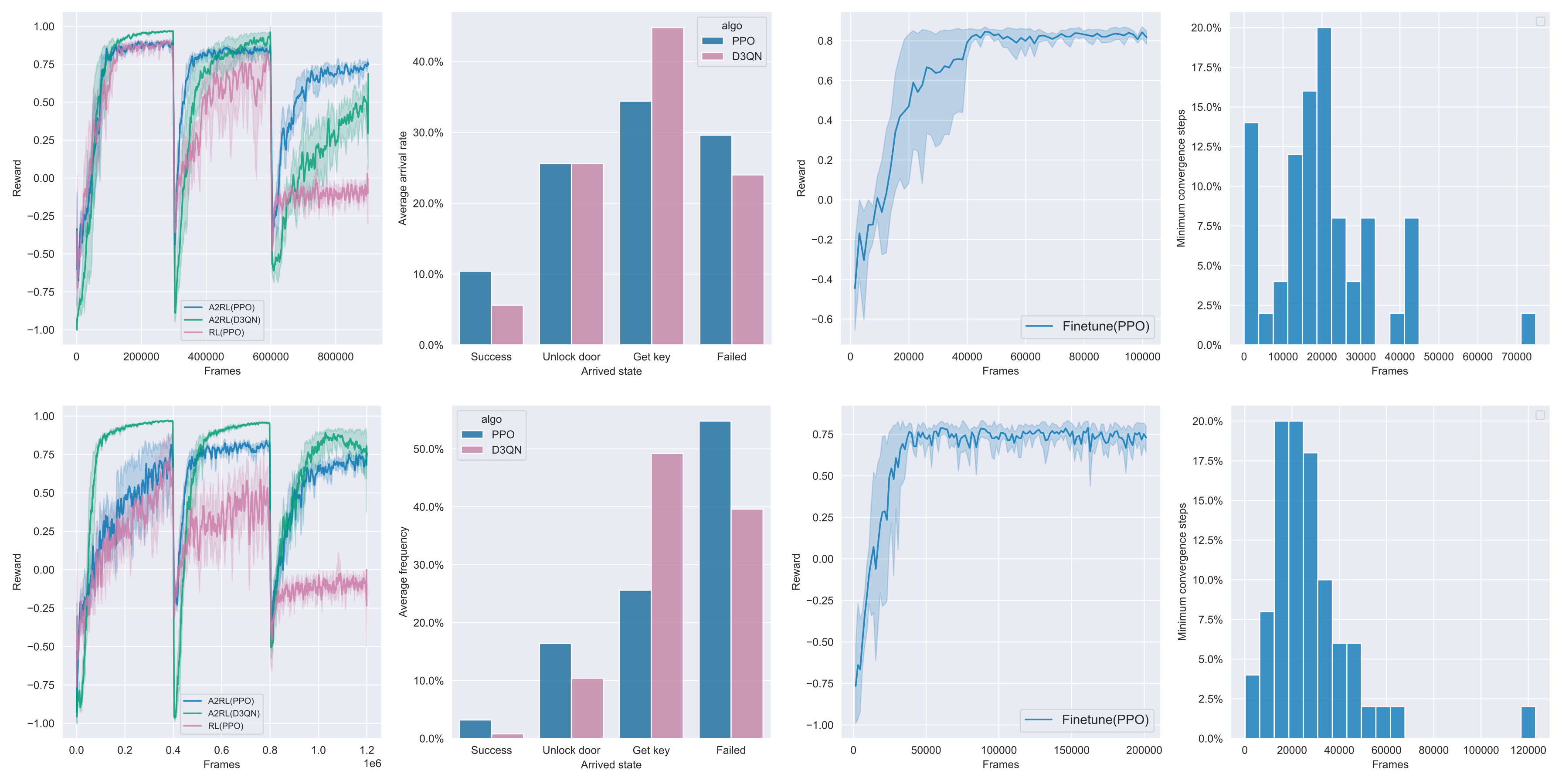
2nd col.: testing reward in 50 random maps. The abstracted model did extrapolates;
3rd-4th cols.: continual learning in 50 random maps, requires much less training data.
Summary
Learning ⬌ Abstraction ⬌ Reasoning

Abstracting raw traces?
Open problem: Program (grammar) induction with neuro-predicate (concept) invention.
For an under-trained agent, the traces look like this:

- We want model it like \(a^*b^*c^*\), but which segments corresponds to \(a\), \(b\) and \(c\)?
- Needs to learn state perception models \(\phi_a: \mathbb{R}^n \rightarrow \{0,1\},\,\phi_b: \mathbb{R}^n \rightarrow \{0,1\},\ldots\)
- while allowing the alphabet \(\{a, b, c, \ldots\}\) to increase during learning
- and induce rules like \(c\leftarrow a\wedge b\) for high-level planning
- meanwhile, train low-level action models \(\pi_a:\mathbb{R}^n \rightarrow\mathbb{R}^m , \ldots\) to execute the plan
- A possible solution: combining abduction and induction and deep / statistical learning.
Job Opportunity @ Nanjing

- Nanjing University is seeking talented faculty and researchers to persue advancements in the field of classical symbolic AI, statistical relational AI and neuro-symbolic AI.
- We offer all kinds of positions, from postdoc to full professor.
- AI research @ Nanjing is leading by top-notch scholars, such as Stephen Muggleton FREng, Tan Tieniu FREng, and Zhi-Hua Zhou (current President of Trustee Board of IJCAI)